
Как подобрать ключевые слова
Как подобрать ключевые слова для продвижения сайта?

Поисковая система Google постоянно стремится показывать пользователям лучшие результаты поиска, соответствующие их ожиданиям. Отсюда и непостоянство среды Google — алгоритмы постоянно обновляются, и о большинстве обновлений Google громко не говорит. То, что работало всего несколько лет назад, сегодня может быть неактуально. Это как-то заставило изменить подход к позиционированию фраз. Популярное ранее позиционирование по определенному списку фраз перестало работать. Борьба за высокие позиции в рейтинге Google по конкретным фразам уступила место более широкому продвижению, повышению видимости сайта в интернете по широкому спектру фраз. Почему это лучшее решение? Небольшое сопоставление двух подходов поможет вам понять разницу.
Позиционирование по фразам — что это?
Традиционная модель заключается в продвижении вашего сайта по определенному списку фраз. Все действия направлены на то, чтобы сайт занял как можно более высокую позицию в рейтинге Google по заранее определенным выражениям, которыми ограничивается продвижение. Здесь очень важен тщательный анализ ключевых фраз, ведь неправильный их подбор может обернуться пустой тратой не только времени, но и денег.
Затраты в этом случае обычно зависят от определенного количества фраз и их конкурентоспособности, т.е. чем больше фраз и/или чем они более конкурентоспособны, тем выше цена позиционирования. Каждое ключевое слово также может быть оценено индивидуально – есть фразы, которые менее и более конкурентоспособны.
Широкое позиционирование — это относительно новый подход, который отвечает изменчивости среды Google. В этой модели работы они предполагают продвижение всего сайта по практически неограниченному количеству фраз (как общих, длинных хвостов , так и с геолокацией), что позволяет формировать все большую видимость сайта в Google. Список продвигаемых фраз постоянно пополняется – широкое позиционирование открыто и позволяет добавлять новые фразы, соответствующие различным запросам, направляемым пользователями в поисковую систему Google. Повышение видимости всего веб-сайта в поисковой системе имеет большее значение, чем высокие позиции в рейтинге по определенным ключевым словам . Поэтому под видимостью страницы в Google здесь понимается сумма просмотров страницы по всем фразам.
FAQ раздел на сайте
Как создать раздел FAQ на сайте?

FAQ, список часто задаваемых вопросов (англ. Frequently Asked Questions), представляет собой специальную подстраницу, на которой собраны самые популярные вопросы, возникающие у клиентов данной компании или услуги. Практика публикации часто задаваемых вопросов на веб-сайтах почти так же стара, как и сам интернет — первые электронные списки такого типа появились еще до разработки протокола WWW. Сегодня FAQ встречается на миллионах сайтов действующих интернет-магазинов или сервисных компаний по всему миру.
Почему стоит разместить FAQ на сайте?
FAQ оказывает покупателю немедленную помощь — пользователь может быстро найти ответ на волнующий его вопрос, что сокращает путь покупки.
Это экономит время – как для вас, так и для клиента. Независимо от того, отвечаете ли на вопросы исключительно вы или компанией занимается обширный отдел обслуживания клиентов и технической поддержки, каждое взаимодействие требует времени и участия сотрудника. FAQ позволяет пропустить прямой контакт с наиболее распространенными вопросами, но не оставить их без ответа.
Это доказывает, что вы заботитесь о потребителях – в FAQ в понятной, дружественной форме представлены различные процедуры между компанией и клиентом. Прозрачное представление возможностей будущего сотрудничества (в какой бы форме оно ни принималось) — это большая ценность для пользователя, а также отличный способ показать свой опыт, клиентоориентированный подход и завоевать доверие.
Влияние на SEO
FAQ — это полноценная подстраница, которая, как и другие, влияет на позиционирование всего сайта. Это создает большой потенциал для улучшения SEO, в том числе благодаря внутренней перелинковке. Кроме того, это подстраница с большим количеством контента, которую охотно «щелкают», с возможностью систематического расширения контента — веб-роботам это нравится!
Это позволяет Google Featured Snippets появляться — правильно построенная схема вопросов и ответов может рассматриваться Google как достаточно ценная, чтобы отображаться в виде выделенного фрагмента над результатами поиска.
Во многих местах — от крупных интернет-магазинов до небольших сервисных бизнес-сайтов — FAQ, несмотря на опубликованное некачественное исполнение, находится на грани бесполезности. Плохо составленный список часто задаваемых вопросов не только не имеет большой ценности для пользователя, но может даже вызвать у него раздражение и привести к тому, что он перенаправит свои шаги в интернете в другое место.
FAQ – подборка вопросов
Первым шагом, конечно же, будет обращение к вашему опыту и опыту отдела обслуживания клиентов. Вы прекрасно знаете потребности клиентов и темы, которые чаще всего обсуждаются в общении. Также стоит заглянуть на сайты ближайших конкурентов, работающих в той же отрасли — наверняка многие вопросы будут схожими. В случае интернет-магазинов must-have — это, например, четкое представление механизмов оплаты, политики возврата или гарантийных процедур.
Как продвигать сайт
Как продвигать сайт платными и бесплатными методами?

Хотите успешно позиционировать сайт своей компании? Эта задача может оказаться более сложной, чем вы изначально думали. Считаете ли вы, что знания основных принципов SEO достаточно, чтобы создать эффективный план позиционирования и оптимизации сайта, который отразится на растущей видимости сайта в результатах обычного поиска? Не забывайте, что тип бизнеса, которым вы управляете, имеет решающее значение при выборе стратегии SEO. Почему позиционирование сайтов будет немного отличаться от позиционирования интернет-магазина?
Интернет-маркетинг
Поскольку в своей профессиональной жизни вы занимаетесь бизнесом, то наверняка прекрасно понимаете, что без продвинутых маркетинговых мероприятий о развитии компании можно забыть. Раньше для охвата потенциальных клиентов использовались только традиционные каналы. Объявления размещались в газетах, а иногда и на радиостанциях. Компании с большим рекламным бюджетом могли позволить себе купить рекламный ролик на телевидении. Были еще рекламные щиты или листовки. Однако мир постоянно движется вперед, и вместе с развитием технологий меняются и стандарты маркетинговой деятельности. Онлайн-пользователь становится все более и более важным. Хотите успешно привлекать новых клиентов? Инвестируйте в интернет-маркетинг!
Вы сможете эффективно продвигать свой бизнес (не только онлайн) в интернете. Интернет-маркетинг дает много инструментов в ваше распоряжение. Какой из них вы будете использовать? Это только ваше решение. Если вы хотите получить ценный трафик, выберите SEO. Хотите увидеть эффект на следующий день? Делайте ставку на рекламу в платных результатах поиска. Кроме того, также есть деятельность в социальных сетях, контент-маркетинг. Однако помните, что рекламная стратегия всегда должна оптимально соответствовать типу вашего бизнеса. Только тогда у него есть шанс на высокую норму прибыли.
Почему вид деятельности влияет на SEO-стратегию?
Хотите, чтобы ваш сайт занимал высокие позиции в органическом поиске? Одни только благие намерения мало чем помогут. Настало время конкретных действий. Можно повысить узнаваемость своего сайта, инвестируя в позиционирование сайта и позиционирование магазина (в зависимости от типа бизнеса). Если сайт отображается на высоких позициях в рейтинге Google, пользователю будет легче найти его. Наибольший потенциал кроется в результатах поиска, отображаемых на первой странице. Вряд ли кто-то углубляется в поиск дальнейших подстраниц, тем более что Google заботится о том, чтобы пользователь как можно скорее получил ссылки на сайты, где он может найти ценную информацию.
Как поменять домен с минимальными потерями
Как поменять домен с минимальными потерями для SEO?

Переезд на новый домен — это всегда большая проблема. Важно перенести все файлы, чтобы сайт продолжал нормально функционировать. Также нужно подготовиться к переезду в плане SEO, чтобы ресурс не пропадал в поисковой выдаче и не терял значительную часть своего органического трафика.
Когда переходить на новый домен
Многим владельцам сайтов грозит переезд. Это может быть смена хостинга или CMS, переход на защищенный протокол HTTPS или смена доменного имени. Последнюю причину стоит рассмотреть подробнее.
Переезд на новый домен чаще всего нужен в двух случаях:
1. Расширение бизнеса. Владелец сайта хочет масштабировать бизнес по всей стране и понимает, что для каждого региона лучше делать отдельные страницы. Для каждого города покупается домен.
2. Ребрендинг – изменение названия бренда, дизайна, позиционирования или идеологической составляющей.
В этом пошаговом руководстве будет более подробно рассмотрено, что следует учитывать перед ребрендингом, чтобы изменение доменного имени не испортило всю вашу прошлую работу по SEO.
Шаг 1: Резервное копирование
Перенести многостраничный ресурс в один клик нереально. Необходима тщательная подготовка. Она начинается с резервного копирования. Перед переездом на новый домен сделайте полную копию сайта. Таким образом, вы всегда сможете вернуться к рабочей версии, если что-то пойдет не по плану.
Шаг 2: Выбор доменного имени
Домен оказывает существенное влияние на ранжирование ресурса. Google учитывает его возраст, авторитетность ранее размещенных на нем сайтов, геолокацию и гиперссылки. У перепродажных доменов есть одна особенность. У них может быть плохая история. Бывший владелец получил штраф за неуплату или поисковик наложил санкции на ресурс. Перед выбором домена всегда важно проверить его историю. SEO-специалисты рекомендуют на всякий случай проверить новый адрес, чтобы в будущем не было сюрпризов.
Для проверки истории домена можно использовать множество различных онлайн-инструментов, даже Google Search Console. Если вы видите, что санкции все-таки были применены, убедитесь, что на данный момент адрес не нарушает никаких правил поисковой системы, и запросите проверку Google.
Если говорить конкретно о выборе нового имени, то хорошим решением будет совместить в названии сайта название бренда и, возможно, отсылку к вашей деятельности. Это повысит узнаваемость бренда, и со временем Google начнет показывать сайт. Это может произойти, даже если пользователь ввел неправильный поисковый запрос.
Продолжить чтение “Как поменять домен с минимальными потерями”
Навигация на сайте
Как проработать удобную навигацию на сайте?

Если вы хотите обеспечить видимость своего веб-сайта в интернете, необходимо обращать внимание не только на контент, публикуемый на данном веб-сайте, но и на его структуру. Создание соответствующих подстраниц может сделать данный веб-сайт более удобным для пользователей и для роботов Google. Как создать правильную структуру сайта?
Какова структура сайта и из чего он состоит?
Структура сайта — что это? Проще говоря, это иерархия отдельных подстраниц. Благодаря этому можно эффективно перемещаться по сайту пользователям и роботам Google. Это своего рода путеводитель по сайту, информирующий о том, какие категории и как связаны друг с другом. Хотя структуре веб-сайта часто уделяется мало времени, стоит помнить, что она часто является основой деятельности по позиционированию веб-сайта.
Google хочет предоставить пользователям веб-сайты, которые отвечают на их вопросы. Если контент, представляющий интерес для определенных людей, появляется на подстраницах и они правильно проиндексированы, пользователи найдут его в органической выдаче, что увеличит посещаемость сайта. Структуру сайта можно разделить на:
• категории, которые являются наиболее важными подстраницами данного веб-сайта. Пользователь должен иметь доступ к ним прямо из меню;
• подкатегории, которые расширяются на основных подстраницах. Обычно к ним можно получить доступ, развернув список выбранной категории в меню;
• дополнительные подстраницы, часто (но не всегда) входящие в основные категории, такие как “Контакты“, “О нас” и другие.
Соответствующая структура веб-сайта особенно важна в случае сложных веб-сайтов, таких как интернет-магазины, предлагающие различные виды товаров. Также стоит помнить, что меню данного сайта лучше всего размещать вверху, чтобы пользователю, зашедшему на сайт, не приходилось долго его искать. В некоторых случаях также рекомендуется размещать ссылки на категории в нижней части сайта, но тогда нужно убедиться, что пользователю не нужно прокручивать страницу, чтобы найти их.
Что нужно помнить при планировании структуры сайта?
Не всегда легко обеспечить, чтобы структура веб-сайта была последовательной и обеспечивала удобство для пользователей, посещающих веб-сайт. При создании своего веб-сайта стоит помнить о нескольких шагах, которые помогут создать отдельные подстраницы таким образом, чтобы их можно было найти в результатах поиска Google и представлять собой интересные категории для людей, заходящих на веб-сайт.
Как продвигать сайт
Как продвигать сайт платными и бесплатными способами?

Результаты поиска делятся на бесплатные и платные. Высокие, свободные позиции чаще всего достигаются благодаря позиционированию, то есть действиям, повышающим видимость сайта в поисковой системе. Платные результаты поиска являются результатом кампании Google Ads. Каковы характеристики этих двух видов интернет-продвижения? Что выбрать для собственного бизнеса? Об этом можно прочитать в тексте.
Что такое позиционирование сайта?
Позиционирование — это комплекс мероприятий, которые позволяют повысить видимость сайта в поисковой системе. Чаще всего, когда пишется о поисковой системе, имеется в виду Google — самая популярная поисковая система в мире.
Существует более 200 факторов, влияющих на ранжирование в поисковых системах. Именно неявные алгоритмы решают, какой результат является ценным и должен быть включен в результаты поисковой системы. Можно сказать, что позиционирование — это адаптация сайта с точки зрения факторов ранжирования, которые могут быть разными для отрасли и даже запросов.
Контент-маркетинг и позиционирование сайта
Поисковая система Google придает большое значение полезным текстам на сайте, для которых характерны:
• уникальность;
• добавленная стоимость для пользователя;
• техническая оптимизация;
• ответ на введенный запрос в соответствии с намерением пользователя сети интернет.
Контент не должен дублироваться, например, с сайтов производителей оборудования или других сайтов. Описания должны побуждать клиента к их прочтению, а после того, как он дочитал их, давать ему полезную информацию об услугах или товарах.
Важным элементом является и техническая часть, в том числе соответствующая насыщенность и распределение ключевых слов в тексте, включая родственные слова или правильная иерархия заголовков “H”, другие дифференцирующие элементы, такие как графика, таблицы или списки.
Как продвигать интернет-магазин
Как продвигать интернет-магазин в результатах поиска?

Привлекательное товарное предложение, конкурентоспособные цены, широкий выбор, профессиональное обслуживание клиентов… вот те факторы, которые играют ключевую роль в развитии интернет-магазина и формировании положительного имиджа бренда. Однако не они приносят трафик на сайт, а значит, не благодаря им потенциальный покупатель направляется в ваши интернет-магазины. Для этого необходимо правильно его позиционировать, то есть совершить ряд действий, благодаря которым он будет виден в поисковых системах, а Google поместит его выше в рейтинге. Конкуренция растет, интернет-продавцов становится все больше, поэтому нужно позаботиться о своем высоком положении.
Как правильно позиционировать интернет-магазин — первые шаги
Онлайн-продавец, если он хочет быть заметным в сети и постоянно расширять круг своих клиентов, должен сотрудничать с Google и подстраиваться под его требования. При запуске интернет-магазина вы должны убедиться, что у ваших пользователей есть безопасное соединение, то есть протокол HTTPS. Это один из факторов ранжирования и сигнал для потенциального клиента о том, что предоставляемые им данные защищены и не будут использованы посторонними лицами.
Инструменты SEO могут помочь вам позиционировать свой интернет-магазин. Вам не нужно вкладывать средства в дорогие приложения и плагины, стоит использовать бесплатные, такие как Google Search Console и Google Analytics. Первый из них предназначен для оптимизации и мониторинга сайта, второй — для веб-аналитики. Прежде чем приступить к правильному позиционированию своего интернет-магазина, следует поставить перед собой цель, а значит ответить на вопрос – чего именно я хочу добиться, зачем им нужен хорошо позиционируемый сайт? Какова может быть ваша цель? Продвижение конкретного товара или товарной категории, а также повышение узнаваемости вашего бренда среди интернет-пользователей (особенно когда вы начинающий продавец). Цели, которые вы перед собой ставите, помогут вам на следующих этапах позиционирования.
Как работают поисковые алгоритмы
Как работают поисковые алгоритмы Google?

Пингвин, Колибри, Панда – три милых для многих животных. Каждый из них имеет свои уникальные особенности. Каждый из них по-своему красив и уникален. И хотя пользователи интернета ассоциируют их с живыми существами, люди, создающие новые веб-сайты, в том числе, те, которые могут отображать информацию об этих животных, связаны не столько с миром животных, сколько с виртуальным миром, потому что это названия алгоритмов Google.
При разработке и внедрении веб-сайтов, а также проведении маркетинговой деятельности для клиентов, маркетинговые компании лицом к лицу столкнулись с тремя алгоритмами Google:
- 23.02.2011 – Panda
- 24.04.2012 – Pinguin
- 26.09.2013 – Colibri
Некоторые вещи находятся вне контроля SEO-специалистов и маркетологов. Однако к капризам алгоритмов стоит подготовиться.
Google – это не только поисковая система. Это компания, которая ориентирована на зарабатывание денег. Как и все, потому что для этого он был воплощен в жизнь. Поэтому, если вы решите перейти на веб-сайт, вы сами определяете условия, которые он устанавливает. Познакомьтесь с ними, и ваш сайт получит более высокие оценки при классификации, благодаря чему он будет показан более широкой группе пользователей – вашим потенциальным клиентам. Многие из них могут стать вашими целевыми клиентами, многие — даже постоянными.
Panda
Google выпустил алгоритм, основной задачей которого было распознавание высококачественных веб-сайтов с высокими поисковыми рейтингами. С другой стороны, наказывались те (часто в полном объеме), чья информационная и структурная ценность была слабой и некачественной.
Но Google обнаружил способ поднять ваш сайт. В блоге Google есть запись со списком факторов, которые будут важны при классификации страниц.
Google сосредоточил внимание на контенте и его:
- авторитете
- надежности
- стадии продвижения
- длине
- уникальности
- лингвистической корректности
С другой стороны, Google считал категориальной ошибкой использование дублированного, а также лингвистически и фактически некачественного контента.
Pinguin
Этот алгоритм Google с 2012 года установил несколько иные правила для владельцев веб-сайтов.
Основная цель Penguin – ограничить доверие тех сайтов, на которых есть неестественные ссылки, чьей задачей было поднять позиции в поисковой системе.
Какие ссылки были полезны для Penguin? Его благосклонность завоевали те, кто пришел с признанных и уважаемых веб-сайтов. С другой стороны, страницы, содержащие ссылки с малоизвестных и небольших сайтов, не производили на него впечатления. После выбора Penguin оценки впечатлений значительно изменились. Оба алгоритма в большинстве случаев наказывали сайт, вызывая большой беспорядок в результатах и рейтингах поисковой системы.
Какую политику внес этот алгоритм? Удаление неестественных ссылок и, если это невозможно, Google мог не учитывать их при классификации сайта.
Поиск информации в “Яндекс” и Google
 Результаты поисковой выдачи порой далеки от совершенства: веб-страницы с неактуальной информацией, неподходящие к контексту запроса картинки, всплывающие блоки с рекламой.
Результаты поисковой выдачи порой далеки от совершенства: веб-страницы с неактуальной информацией, неподходящие к контексту запроса картинки, всплывающие блоки с рекламой.
Проблема распространенная, но решаемая – достаточно разобраться в том, как образом повысить эффективность поиска в интернете. Хитростей поисковики скрывают много – пора выяснить то, о чем молчат даже веб-мастера.
Сплошная математика
Поисковые сервисы «Яндекс» и Google старательно реагируют на арифметические знаки и символы, добавляемые рядом со словами в пустующее текстовое поле. Способов разнообразить запрос предостаточно, но ориентироваться рекомендуется на следующие вариации:
- Исключение из поиска. Если при поиске ингредиентов для салата появилась необходимость исключить интернет-магазины или сайты доставки еды, то «лишняя» информация буквально вычитается из текстового запроса («салат оливье -доставка»).
- Синонимы. Соседние по смыслу запросы подмешиваются к поиску с помощью символа ~. Если появилось опробовать оливье не в форме салата, но еще и в произвольном варианте, то запрос должен выглядеть следующим образом ~салат оливье рецепты.
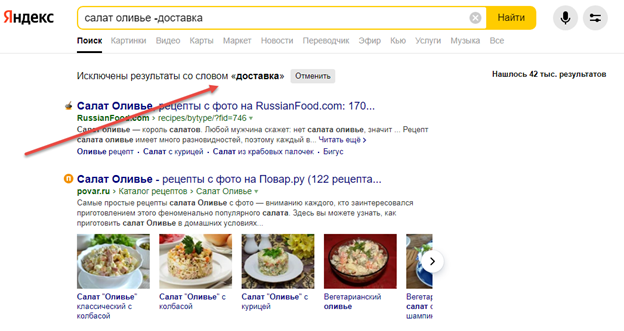
- Неопределенный запрос. Если к «Яндекс» и Google приходиться обращаться с сомнениями из-за не составленного заранее запроса, то символ * облегчит жизнь. Достаточно ввести следующий текст «список лучших блюд * на праздник» и поисковики подберут подходящую информацию.
- Точное совпадение. Но важнее синонимов и сомнений оператор “”, разрешающий искать лишь сайты с точным совпадением с запросом, причем в заданном формате.
Разграничение поиска с помощью операторов
Кроме арифметических знаков повлиять на результаты выдачи разрешают операторы – специальные команды, добавляемые в поисковую строку и дополняющие запрос. Как вариант команда site: разрешает искать информацию лишь на выбранном сайте (вот пример – site:www.dotabuff.com “puck”).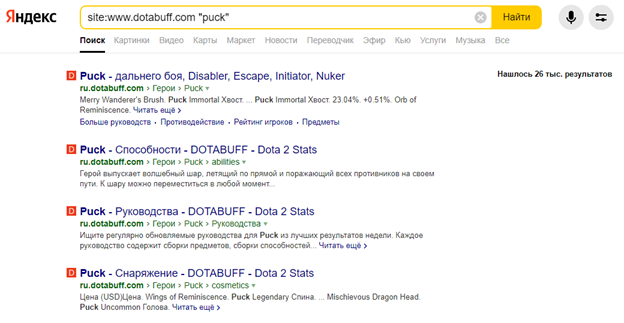
Оператор inurl: разрешает находить слова в URL-адресе (срабатывает лишь в Google), а allintitle – в заголовке веб-страниц. Если уж появилась необходимость в точном совпадении, то дополнительная конкретика не повредит.
Среди иных любопытных находок – просмотр количества ресурсов, ссылающихся на конкретный сайт. Проверка происходит с помощью оператора link и url-адреса, разделяемого двоеточием (link:google.com).
Что такое “след”? Справочник по идентификации личности в интернете
 Админы выбрались на природу и, рассаживаясь вокруг костра, начинают рассказывать страшные истории про хакеров. Вам интересно, как начинает работать хакер? Что такое след заголовка?
Админы выбрались на природу и, рассаживаясь вокруг костра, начинают рассказывать страшные истории про хакеров. Вам интересно, как начинает работать хакер? Что такое след заголовка?
В российских реалиях этот вид деятельности, изначально подготовленный к атаке или аудиту безопасности, называется сетевой разведкой или поиском следов (следа) по названию.
Говоря простым языком, это набор действий, выполняемых аудитором-хакером, которые направлены на сбор как можно большего количества информации об атакованном сервере, организации или компьютере жертвы. Часто такие действия называют белым интеллектом, то есть OSINT.
Информация, которая может быть полезна хакеру:
- список веб-сайтов (и whois-доменов) жертвы и опубликованных на них данных, а также их структура (включая скрытые файлы и папки), информация о скриптах на сервере;
- целевой IP и MAC-адреса;
- версии систем, на которых работает жертва или сервер;
- всевозможная информация о пользователях и сотрудниках системы;
- информация о системах предотвращения вторжений (IDS);
- физическое построение внутренней сети жертвы;
- запуск сетевых сервисов (программ) и их версий на сервере или компьютере жертвы;
Большой объем информации необходимо получать вручную путем поиска в различных поисковых системах интернета, а также путем сканирования структуры страниц жертвы с помощью словаря или методом грубой силы (поиск скрытых файлов, которые могут скрывать интересную или секретную информацию). Часто на хостинге скрыты конфигурационные файлы, файлы паролей, проприетарные административные панели, незащищенные загрузчики файлов и интересные фотографии администраторов.
Для этих целей используются следующие интересные инструменты:
- команды поисковой системы Google – этот тип атак с использованием доступной информации в интернете часто называют взломом Google. Информацию о готовых командах для поиска потенциально уязвимых сайтов стоит поискать в интернете, такие списки часто называют “гугл-придурками”. Также есть такие инструменты, как SiteDigger 3.0. Еще стоит использовать специализированную поисковую систему для устройств, потенциально уязвимых для атак Shodan (http://www.shodanhq.com/);
- вы можете использовать инструмент IndirScanner (требуется интерпретатор Perl), а также отличный инструмент от OWASP под названием DirBuster для изучения скрытой структуры веб-сайта (файлов и папок, размещенных на сервере без ссылок из любой точки интернета). Еще один интересный инструмент – Burp Spider. С помощью этих инструментов мы можем искать на веб-сайте данные, скрытые для пользователей без специальных знаний (это тоже следы);
Продолжить чтение “Что такое “след”? Справочник по идентификации личности в интернете”
Как разработать эффективную контентную стратегию YouTube
 Если вы планируете стать создателем контента на YouTube, важно, чтобы у вас была очень жизнеспособная стратегия контента, запланированная заранее.
Если вы планируете стать создателем контента на YouTube, важно, чтобы у вас была очень жизнеспособная стратегия контента, запланированная заранее.
Несколько советов, которые могут помочь вам сформулировать эффективную стратегию контента YouTube:
1. Заранее выберите свою нишу контента
Создание видео, которое становится вирусным, не обязательно должно включать в себя кошек, говорящих как люди, или экстремальный розыгрыш над ничего не подозревающей публикой. Зрители могут смотреть различные видеоролики на YouTube, чтобы просто расслабиться, исследовать или даже узнать что-то полезное. Итак, выберите нишу, в которой вы можете быть хороши. Это может быть что угодно. Это может быть раздача рецензий на фильмы, обзоры ресторанов, обзоры гаджетов, как сделать лучшее из отходов, поделки своими руками, уроки макияжа, советы по запоминанию вещей или даже уроки игры на гитаре. Зрители должны найти ваше видео интересным и информативным. Содержание является королем в эти дни, чтобы разработать свою стратегию контента YouTube, выберите нишу, в которой Вы хороши и можете в конечном итоге процветать. Также важно сделать видео релевантными и интерактивными, найти причины, по которым ваша аудитория должна смотреть ваше видео.
Продолжить чтение “Как разработать эффективную контентную стратегию YouTube”
Как работают алгоритмы выдачи Google
 Несколько лет назад поисковая система Google отображала результаты поиска в виде простого списка. Каждый поиск давал идентичный образец результатов. Каждый результат содержал заголовок страницы, URL-адрес и фрагмент описания страницы. В настоящее время, в зависимости от запроса, поисковая система также представляет рекомендуемые фрагменты с ответом, панели знаний, торговые объявления, карусели продуктов или даже самые важные подстраницы главной страницы веб-сайта.
Несколько лет назад поисковая система Google отображала результаты поиска в виде простого списка. Каждый поиск давал идентичный образец результатов. Каждый результат содержал заголовок страницы, URL-адрес и фрагмент описания страницы. В настоящее время, в зависимости от запроса, поисковая система также представляет рекомендуемые фрагменты с ответом, панели знаний, торговые объявления, карусели продуктов или даже самые важные подстраницы главной страницы веб-сайта.
В настоящее время результаты поиска представляют собой не только простые ссылки, но также фотографии, видео и даже интерактивный контент. Каждый поиск имеет разный состав и формат результатов. Такое разнообразие форм и мест представления результатов играет ключевую роль в их восприятии пользователями. Исследователи обнаружили, что при изменении результатов зрение пользователей будет следовать за прыгающим мячом на странице, который отражается в визуально привлекательных местах или ключевых словах, связанных с запросом.
Именно графические элементы и ключевые слова теперь привлекают внимание пользователей поисковой системы (в случае существенных запросов пользователи больше ориентируются на ключевые слова, чем на фотографии и графические элементы, в случае запросов о покупке или развлечениях они чаще смотрят на изображения). Визуальные элементы и фразы определяют схему восприятия результатов. Поскольку эти элементы несколько разбросаны, пользователь переводит взгляд с одного на другой.